
Top AI Achievements of 2025 (part 3)
It’s only been a few months since our last article on AI-related achievements of 2021, and lots of new incredible inventions have already come up. And not just some minor improvements of existing neural networks, but potential candidates for real breakthroughs. This article will describe some of these models and approaches, explain how they work and why they are significant.
So, AI achievements of 2025, part III, let’s go!
Table of Contents:
Codex
In our previous article, we have mentioned Copilot in the ‘Honorable Mentions’ section. Although Copilot has great potential, it is still raw and can only solve relatively easy tasks. However, there is something much bigger behind Copilot. And that is Codex.
Codex is an AI system created by OpenAI. It is the model that powers GitHub Copilot, and it is capable of translating natural language to code. Codex is already proficient with several popular programming languages (including Python, JavaScript, Go, etc.), and it has been announced that more languages (like Java) will be added in the future. According to GitHub, about 30% of code in some languages has been written using Copilot.
How Does It Work?
Codex is a descendant of GPT-3, which means it has similar abilities and techniques. In particular, Codex is based on the work of transformers. However, Codex was trained not only on natural language but also on billions of lines of publicly available code (including the code in public GitHub repositories). As a result, Codex can produce working code responding to the prompt in a natural language. That is, Codex is a GPT-3 model, fine-tuned for use in programming applications. Moreover, Codex has 14KB of memory (while GPT-3 has only 4KB), so it can take into account three times more contextual information than its predecessor.
Why Is It Innovative?
Codex is not just a simple autocomplete tool but a real AI-based partner that can significantly speed up the process of writing code. Instead of browsing through Stack Overflow searching for the right syntax, programmers can simply type what they need in natural language and receive code that already works. It is not just convenient but highly time-saving.
Use Cases
Codex was designed to map simple problems to existing code, which is described by developers as the least fun part of programming. Therefore, its first and primary use case is to write code, which can be used almost anywhere: to conduct calculations and text preprocessing, create tests and simple applications, build graphs, and process images. The list goes on. There are already dozens of demos of Codex which show all the possibilities of this model.
Final Words
Indeed, Codex is quite raw at the moment. It cannot solve complex problems or write entire applications. However, it is the first step towards such functionality.
For now, it is meant to make programming faster rather than replace it. But who knows, maybe it will become a real programmer one day🤔
Pathways
Have you ever been annoyed by the fact that for each new problem, you have to develop a separate machine learning model? Why can’t my text classifier work equally well for spelling correction? Unfortunately, machine learning models need to be trained on a specific dataset to perform well in a particular task. However, this might not be the case anymore.
Google has recently introduced Pathways – a next-generation AI architecture that can potentially handle multiple tasks simultaneously.
How Does It Work?
Pathways differs from previous models so that it does not forget everything it has learned so far. Instead, it uses this knowledge to learn new tasks faster and more effectively. This corresponds to how people learn new stuff since we don’t usually start from scratch but instead use our existing knowledge and accumulate new one.
Pathways has not been released yet – Google is only developing it, so the math behind it is still unknown. But from what we see in the figure below, the model will be trained on multiple datasets with different inputs. When working on a problem, it will use only the necessary parts, so not all neurons will be activated. We might also expect it to use the knowledge acquired from previous tasks, which will increase the model’s ability to generalize.
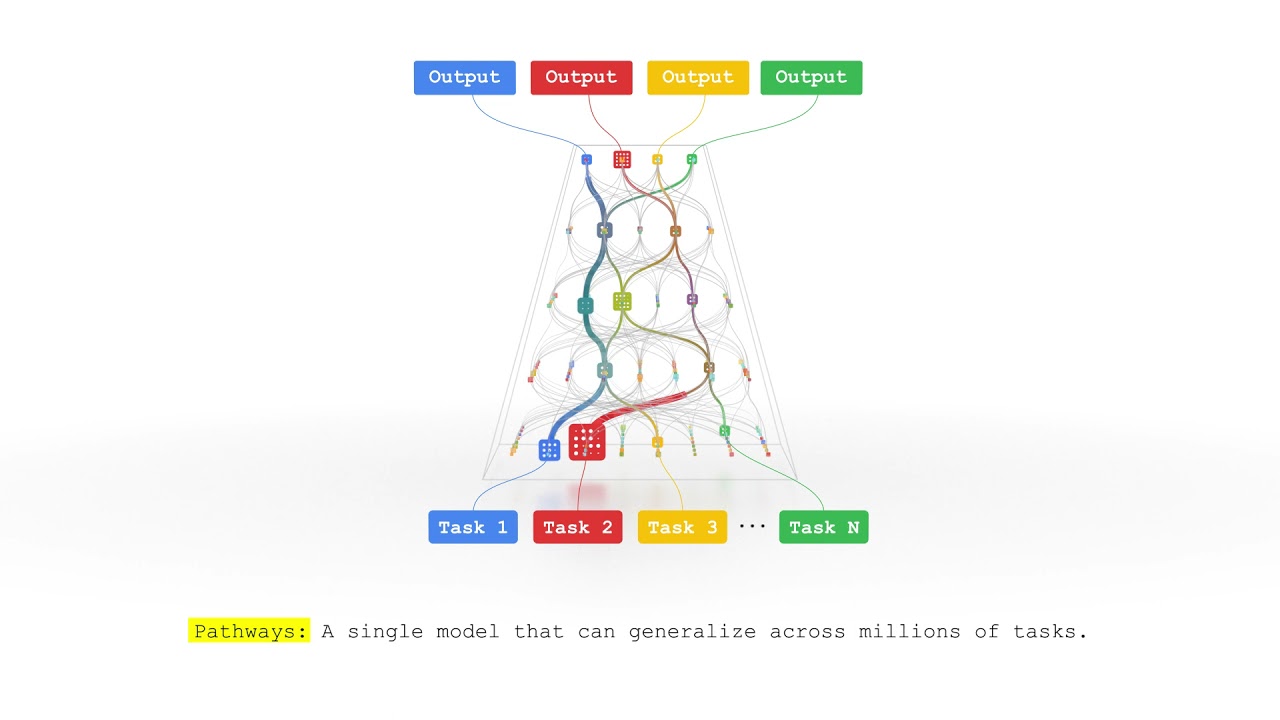 The visualization of Pathways – how it will work (source)
The visualization of Pathways – how it will work (source)
Why Is It Innovative?
Pathways is an entirely novel way to look at artificial intelligence. It addresses many of the weaknesses of existing systems and aggregates their strengths. For instance, instead of doing only one thing, a single model will perform well on thousands of different tasks.
Apart from that, Pathways enables us to build multimodal models that will be able to perceive different types of inputs at once: images, text, sensor data, etc. Multimodality has an advantage over current models since it provides more insights and makes the results less biased.
Finally, Pathways implies a huge sparse model, which means that only a fraction of it will be activated as needed. Current models are dense, meaning that all neurons must be activated to accomplish a task. On the other hand, Pathways will be much more like a human brain – using only the necessary parts but doing it much more efficiently. Such models already exist, and they show remarkable results consuming much less energy.
Use Cases
Pathways is intended to become a machine learning model capable of solving various problems. Therefore, it can potentially be used for anything that requires ml development services: from price prediction to anomaly detection.
Final Words
Even though the model is not out there yet, it can become the next revolution in artificial intelligence development services. We might expect significant changes in this field if Pathways turns out to be what it is designed to be.
T0
T0 is a series of encoder-decoder models by Hugging Face. The zero in the name stands for zero-shot task generalization, which implies that the model can work even with the data and problems it has never seen before. Developers claim that T0 outperforms GTP-3 on many tasks, being 16 times smaller. The results for T0 task generalization compared to GPT-3 are shown in the figure below.
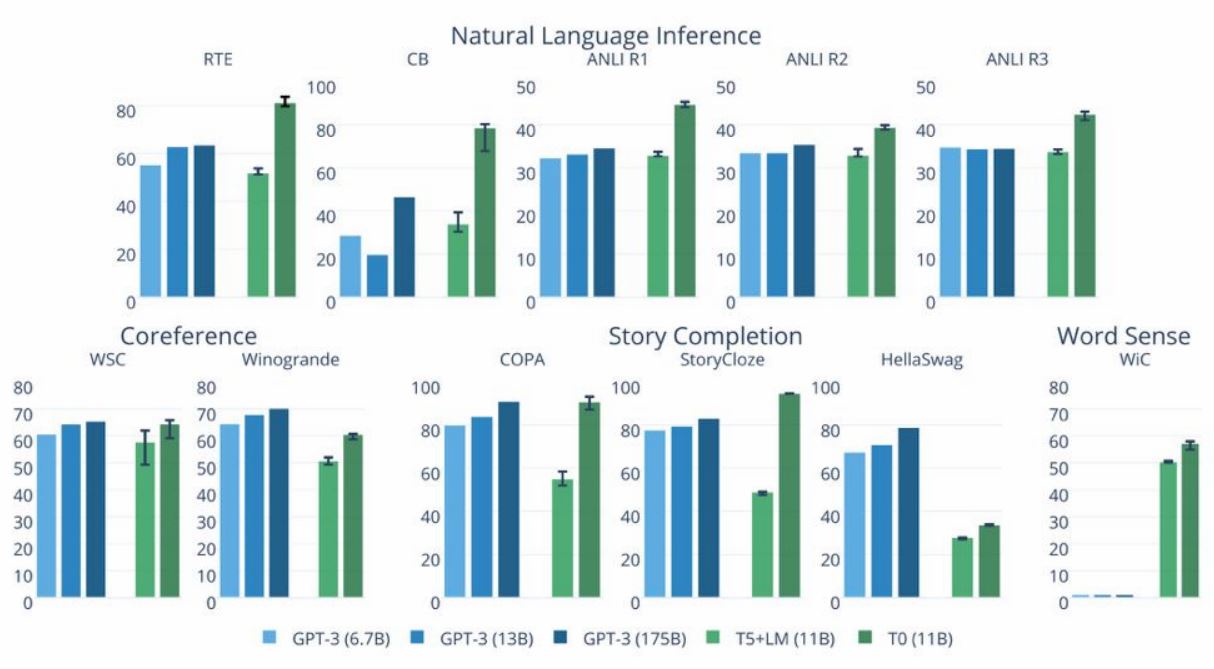 T0’s generalization accuracy in comparison with other models in several tasks on various datasets (source)
T0’s generalization accuracy in comparison with other models in several tasks on various datasets (source)
How Does It Work?
T0 contains 11 billion parameters (not that small after all, ha?), and it is based on Google’s T5, a transformer-based language model. Thousands of additional training steps were conducted to fine-tune it on new problems with previously unseen inputs.
T0 was trained on multiple English supervised datasets converted into prompts. Each prompt has several templates constructed by various formulations, allowing the model to perform well on entirely new tasks.
As said earlier, T0 is the encoder-decoder model. The encoder receives the input text, and the decoder produces the target text. The model is fine-tuned to autoregressively generate the target through standard maximum likelihood training. More details on the training process can be found on the official website.
Why Is It Innovative?
T0 sets new records in zero-shot generalization. Its novel way of training (and the format of training data in particular) allows it to work exceptionally well on previously unseen tasks. Moreover, it will decrease the model’s size, making it faster and more efficient.
Use Cases
T0 is a multi-task language model, which means it can perform inference on different natural language processing tasks. Among them: sentiment analysis, question answering, text summarization, topic classification, paraphrase identification, and many others.
For example, you can ask: “Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy”, and the model will hopefully generate “Positive.” This is an example of sentiment analysis.
Here is another use case. You can ask: “Is the word ‘table’ used in the same meaning in the two following sentences? Sentence A: you can leave the books on the table over there. Sentence B: the tables in this book are very hard to read.” And the model will probably answer “No.”
Many more examples are shown on the official page and in the figure below.
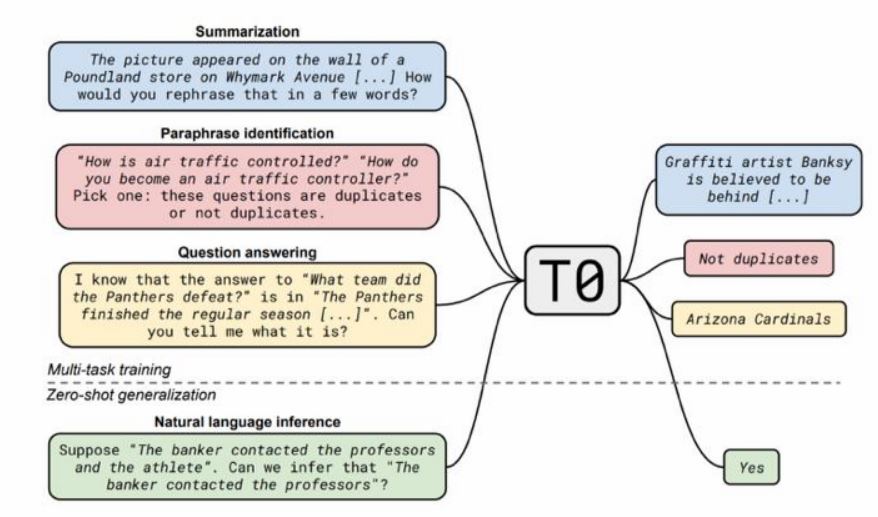 A few examples of T0’s possibilities (source)
A few examples of T0’s possibilities (source)
Final Words
T0 is the new state-of-the-art model for natural language processing. It outperforms the GPT-3 model, which is considered one of the best in the field, in many tasks. It is also much smaller, and it is publicly available so that any researcher can use it for their own purposes.
And although the model requires non-trivial computational resources and cannot work with code (unlike Codex) or non-English texts, it is definitely a breakthrough in NLP. Hugging Face is continuing its research, so we can expect even more efficiency and accuracy in the future.
GSLM
Textless NLP – such an ambitious name for a model, isn’t it? However, scientists at Facebook AI claim to have developed the first high-performing NLP model that relies solely on audio – GSLM (Generative Spoken Language Model).
This project has gathered researchers from various teams across the Facebook AI: signal processing specialists, speech processing engineers, data scientists, computer linguists, psycholinguists, etc. Together they managed to create a truly innovative model that can address some of the problems of modern NLP systems.
How Does It Work?
GSLM has three components. The first one is an encoder that converts speech into discrete units that represent sounds. These discrete units are called pseudo-text. Several state-of-the-art approaches have been tested for the role of an encoder, and HuBERT provided the best overall result.
The second component is an auto-regressive language model, which can predict the following units of text based on the previously seen ones. A multistream transformer with multiple heads has been used for this purpose.
The final component is a decoder that converts units back into sounds. This task was given to Tacotron 2 – a standard speech-to-text system.
The entire system has been trained on over 6000 hours of audiobooks with no text or labels. The baseline architecture of the model can be seen in the figure below.
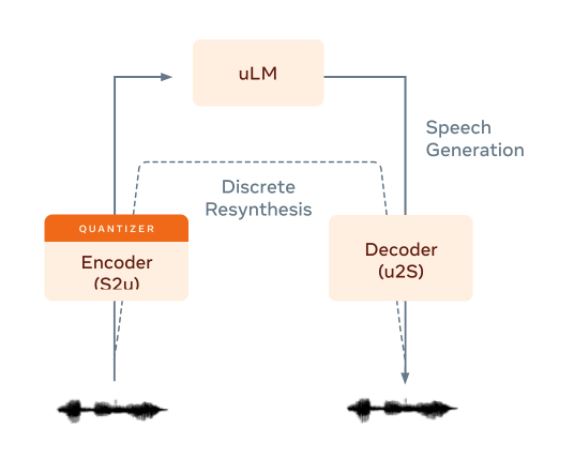 The architecture of GSLM (source)
The architecture of GSLM (source)
Here: S2u stands for speech-to-units, u2S – units-to-speech, and uLM – unit-based language model
Why Is It Innovative?
GSLM is a first-of-its-kind model that brings many novelties into the field. First of all, it removes automatic speech recognition (ASR) systems from the language processing pipeline, thus increasing the speed and accuracy of NLP applications. ASR systems are known for their resource-intensive operations and poor performance, so taking this step away would only benefit the application.
The second significant advantage of textless models is their ability to work, well, without text. Since many human languages don’t have large written datasets, most existing models cannot work with them. The case in Cambodia is one example. Due to Khmer’s complicated and long alphabet, most people prefer to record audio messages instead of typing. As a result, there are no proper text datasets. GSLM can potentially solve this problem and allow training a machine learning model for Khmer.
Use Cases
GSLM can potentially be used just like any other NLP model with the difference that it works with audio instead of text. Sentiment analysis, translation, summarization, question-answering, etc.: all of these are possible with GSLM. However, it can additionally capture other significant features like tone, emotions, or intonations. This ability might bring new insights into our understanding of language processing.
Apart from that, many new applications become possible when removing the speech-to-text step from the process. For example, this work has enabled the first audio-only speech-to-speech translation system, which, combined with GSLM’s ability to work with all the existing languages, can presumably become the first universal translator.
Final Words
GSLM opens many new opportunities for language understanding. Not only does it liberate us from creating massive text datasets for training, but it also allows us to work with rare languages that have little or no written texts. The developers of GSLM already have lots of plans for their model, and we will watch their progress with great interest.
Honorable Mentions
As always, we mention not only the most prominent breakthroughs but also other significant innovations. See below some of the models and approaches that might turn out to have a tremendous impact on AI’s development.
MT-NLG
Megatron-Turing Natural Language Generation models (MT-NLG) is a new transformer model created by NVIDIA and Microsoft. It is also the largest model to date, as it contains 530 billion parameters (GPT-3 has only 175 billion). Developers claim that MT-NLG has surpassed previous state-of-the-art models in some tasks, including natural language inference and reading comprehension.
Training such a colossal model was made possible by several innovations. The most significant one is a new learning infrastructure. The combination of GPU-learning with distributed learning software helped to achieve exceptional training efficiency.
Although there is still a long way to unlocking the full potential of nlp as a service, MT-NLG is definitely a huge step forward.
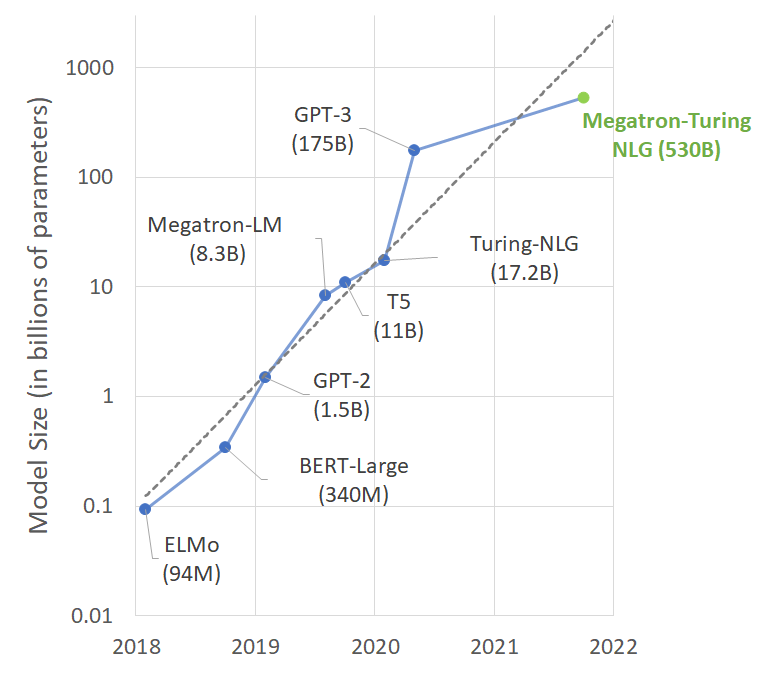 Comparison of sizes of state-of-the-art NLP models (source)
Comparison of sizes of state-of-the-art NLP models (source)
IC-GAN
Instance-Conditioned GAN (IC-GAN) is a new family of models that generate images of previously unseen things. To do so, they use both labeled and unlabeled data. Such an approach extends the GAN framework allowing it to maintain high quality without relying solely on labeled data.
IC-GAN has multiple use cases. For example, it can enrich image datasets with new images that appear very rarely. Or it can be used for the diversification of datasets for object recognition. And, last but not least, it is entertaining to play with the model, and you can even try it yourself here.
 Having only the image shown on the left and a label “Arabian camel,” the model can generate images of a camel surrounded by snow, even though camels do not usually tend to appear in snowy lands (source)
Having only the image shown on the left and a label “Arabian camel,” the model can generate images of a camel surrounded by snow, even though camels do not usually tend to appear in snowy lands (source)
FLAN
Fine-tuned LAnguage Net (FLAN) is another vast language model created by Google AI. Although it is a bit smaller than GPT-3 (FLAN has 137 billion parameters), developers claim it surpasses GPT-3 on some tasks. The reason for that is a new fine-tuning algorithm called “instruction learning,” where the task itself is described in natural language. For example, a simple prompt like “translate ‘what is your name?’ into Spanish”. Such an approach allowed making the model more generalizable in NLP tasks in general rather than fine-tuning it on a specific problem. It turns out to be highly efficient, and some of the results can be seen in the figure below.
 FLAN zero-shot shows higher average accuracy than GPT-3 (even few-shot) in many tasks
FLAN zero-shot shows higher average accuracy than GPT-3 (even few-shot) in many tasks
Conclusion
Quite a productive season we’ve got here, right? Google, Facebook, HuggingFace, NVIDIA – the research is in full swing. The world received several new state-of-the-art models, and we are sure there will be more. So, see you soon in our next article where we will look at the innovations of the last quarter of 2021.
Update: 01.02.2023




