
Top AI Achievements of 2025 (part 2)
You might have already noticed how dynamic the world is. New cool things appear in our lives every day, while many familiar things become obsolete. The same happens in the world of artificial intelligence. New approaches, architectures, models – all of these are contributing to the progress of AI.
It is usually quite challenging to track all the inventions. In this article, we have gathered all the most important ones, briefly describing their significance. We have already published a similar article about the innovations of the first quarter of 2021, so we will concentrate on everything that appeared during the second quarter. And although there were no such significant breakthroughs like CLIP or DALL-E during these few months, there is still a lot of exciting stuff going on.
Without further ado, let us begin!
Table of Contents:
DINO and PAWS
DINO and PAWS are two new methods for model training, simultaneously developed and released by Facebook AI. DINO allows training Vision Transformers (ViT) with no supervision. This is an incredible combination of two of the most promising recent innovations: self-supervised learning and transformers. It can discover and segment objects in an image or a video with no supervision or segmentation-targeted objective. PAWS is a semi-supervised approach that optimizes model training and produces state-of-the-art results using much less computing. DINO and PAWS combined can significantly enhance computer vision systems, making them more efficient and less dependent on labeled data.
 From left to right: original image, supervision model segmentation example, DINO segmentation example (source)
From left to right: original image, supervision model segmentation example, DINO segmentation example (source)
How Does It Work?
To implement self-supervision, DINO utilizes the concept of self-distillation but with no labels at all. Basically, there are two identical networks, one defined as a student and one as a teacher. Both these networks take the same image as input but in different vector representations. The teacher gets the global idea of an image obtained from two partially overlapped patches of great dimensions. The student also receives a local representation of an image acquired by a series of smaller patches.
 From the image of the two kittens above, two global views and several local views are extracted (source)
From the image of the two kittens above, two global views and several local views are extracted (source)
During the training, the student matches local views to the global ones, thus trying to understand that they represent the same image. The teacher network then performs classification based only on the global views while trying to match the output obtained by the student network.
Unlike DINO, PAWS needs a small amount of labeled data. Given an unlabeled training image, several views are generated using random data augmentations and transformations. The neural network is trained to make the representations of these views as similar as possible. The algorithm then uses a random subsample of labeled images to assign a pseudo-label to the unlabeled views. This assignment is conducted by comparing the representations of the unlabeled views and labeled samples. Finally, the model is updated by minimizing a standard classification loss between the pseudo-labels of pairs of views of the same unlabeled image. For more interesting examples refer to computer vision development services.
Why is It Innovative?
Training a computer vision model used to require a lot of time, labeled data, and computing power until this work came along. Algorithms proposed by Facebook AI solve all these problems. The process of self-supervised learning implemented in DINO allows us to train highly accurate models with unlabeled data. At the same time, PAWS dramatically reduces training time using a small set of labeled examples. The latter has also solved a common issue for self-supervised methods – collapsing representations, where all images get mapped to the same representation.
Use Cases:
Both DINO and PAWS greatly enhance the process of model training, making many computer vision tasks easier and the results more accurate. For example, semantic image segmentation services facilitate the tasks from swapping out the background of a video chat to teaching robots to navigate the environment. This is one of the most challenging tasks in computer vision which requires a deep understanding of an image. It is usually achieved by supervised learning. DINO offers an alternative – self-supervised learning. And best of all – the accuracy does not suffer!
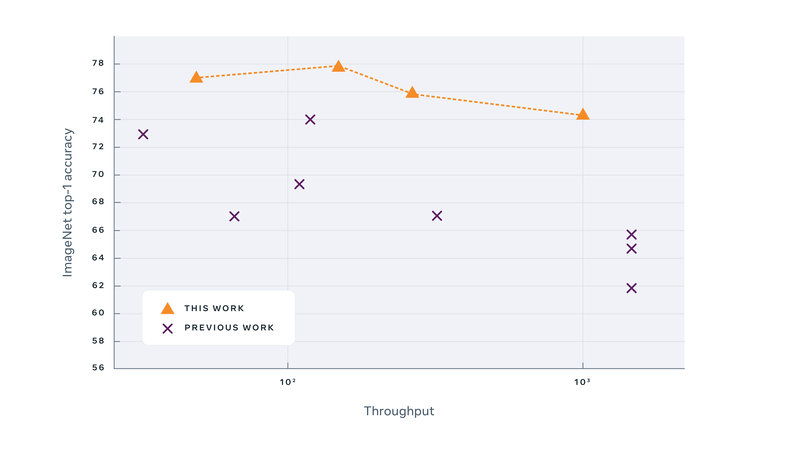 k-NN classification accuracy for various models (source)
k-NN classification accuracy for various models (source)
PAWS, on the other hand, is focused on efficiency rather than performance. It allows training state-of-the-art computer vision models without large-scale computing resources. For comparison, a standard ResNet-50 model needs only one percent of the labels in ImageNet when trained with PAWS. Additionally, it needs 10x fewer steps to reach the same accuracy as previous models. PAWS is an excellent approach for domains where there are few annotated images, like medical imaging.
Final words:
DINO represents a new level in image understanding and segmentation. Not only does it not need labeled data, but it also produces easily interpretable features. Interestingly, this algorithm is also one of the best at identifying image copies, even though it was not trained to do that.
 DINO outperformed two current state-of-the-art models for near-duplicate detection, reaching an accuracy of 96.4% on Flickr 100M dataset (source)
DINO outperformed two current state-of-the-art models for near-duplicate detection, reaching an accuracy of 96.4% on Flickr 100M dataset (source)
With DINO and PAWS, it is possible to build computer vision models that don’t need a lot of labeled data or computing power. These algorithms are also a massive step towards the further development of self-supervised systems and vision transformers. They open a bunch of new possibilities and approaches.
Perceiver
Perceiver is a new state-of-the-art transformer-based model developed by DeepMind. Its uniqueness lies in the fact that it can work with multimodal data. Just like the human brain can simultaneously analyze data received from all our sense organs, Perceiver receives and processes data in different formats. It is a new approach and one more step towards real artificial intelligence.
How Does It Work?
As mentioned earlier, Perceiver is a transformer-based model. However, transformers have a considerable disadvantage – time complexity. These algorithms need to carry out a vast number of operations, which is often computationally infeasible. Researchers at DeepMind have solved this problem by replacing the self-attention layer with a cross-attention one. It allows processing large-scale inputs with linear complexity. Apart from that, all the inputs, whether an image, audio, or sensor data, are converted into bytes, making it possible to simultaneously work with any data type.
Another trick that was used to reduce training time was borrowed from the Set Transformer. This model creates a second version of each data sample, which is a summary of this sample. The Perceiver does a similar thing – a part of it uses the actual data while the other part looks only at the summary. This reduces the training time dramatically.
Why is It Innovative?
The most innovative part of this new model is that it can work with multimodal inputs, while all existing models can only work with one data type, for example, images. Perceiver has also set new records in several tasks. For instance, it has achieved state-of-the-art results in image classification, reaching almost twice the accuracy of the ResNet-50 model.
 Accuracy of different models on permuted ImageNet dataset (source)
Accuracy of different models on permuted ImageNet dataset (source)
Use Cases:
Because of the ability to work with different data formats, Perceiver can be used literally for anything. Google AI Lead, Jeff Dean, has described the Perceiver as “the model that can handle any task, and learn faster, with fewer data.” This ability opens many new opportunities for the AI community and makes us one step closer to true artificial intelligence.
Final Words:
Perceiver is an extraordinary model that scales to hundreds of thousands of inputs of different formats and opens entirely new possibilities for general perception architectures. Despite being a compelling model, Perceiver also has its disadvantages. One of them is overfitting, which is unavoidable in such big models. But researchers did a lot to reduce this effect, and, we should say, quite successfully – Perceiver archives great results on multiple datasets: from audio to images.
HuBERT
HuBERT is another breakthrough made by researchers at Facebook AI. It is an approach for learning self-supervised speech representations, and it matches or surpasses many state-of-the-art systems in speech recognition, generation, and compression. HuBERT is stable and straightforward, and it allows us to work with speech more deeply. Moreover, HuBERT will significantly simplify the development of many applications that work with speech.
How Does It Work?
To learn the structure of spoken input, HuBERT uses an offline k-means clustering step to predict the proper cluster for masked audio segments. The HuBERT model learns both acoustic and language models from these inputs.
The model first builds meaningful representations from unmasked audio inputs. It then uses masked prediction to learn representations by capturing the long-run temporal relationships between the representations to reduce the prediction error. K-means mapping allows the system to focus on modeling the sequential structure of input data. Only the masked regions are subject to the predictive loss, making the model learn representations of unmasked inputs to infer the targets of masked ones.
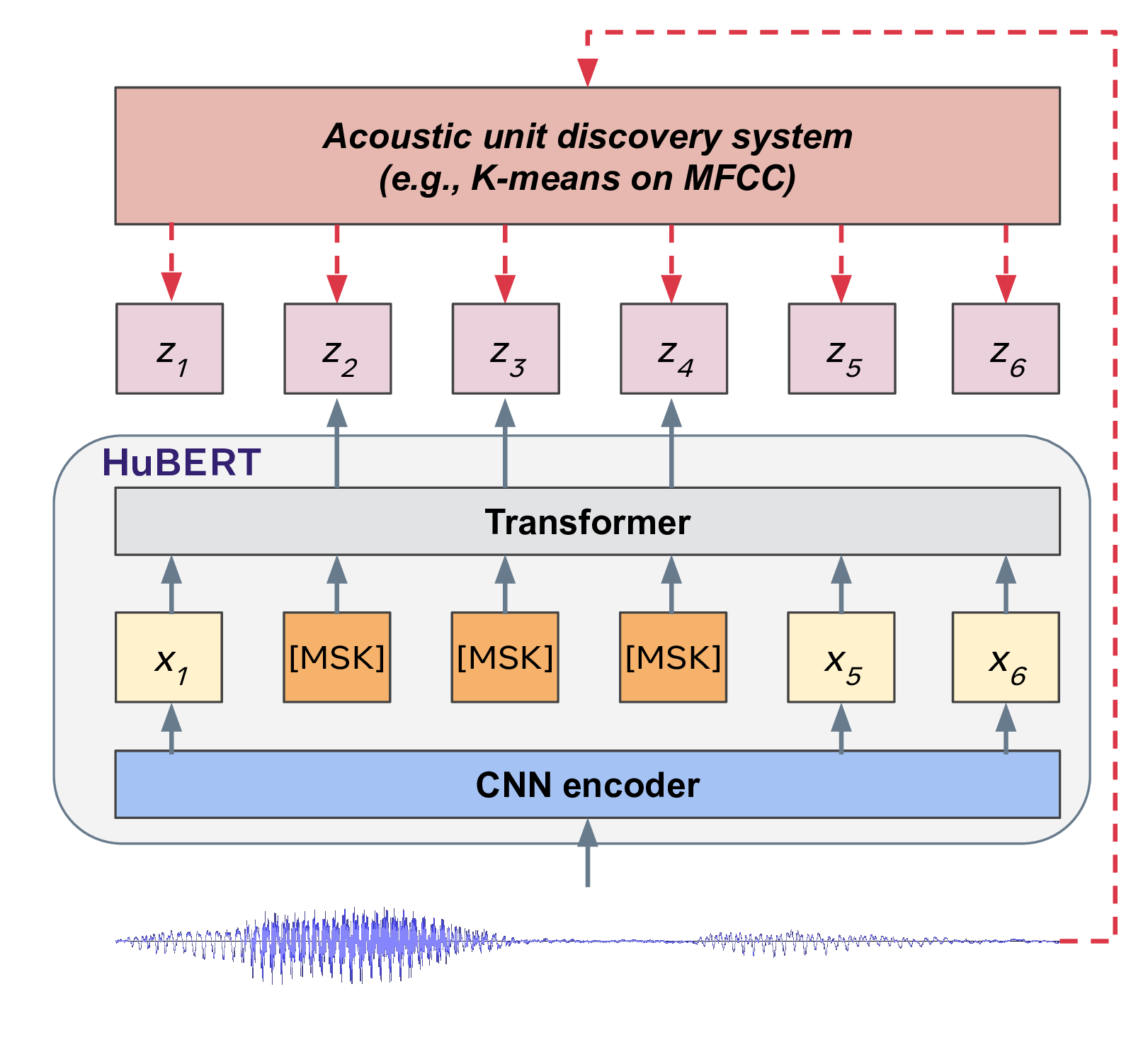 The inner mechanism of HuBERT (source)
The inner mechanism of HuBERT (source)
Why is It Innovative?
HuBERT allows us to develop systems and models trained on audio only, excluding the necessity to translate it into text. We will be able to use all the richness of our language and build brilliant applications. Robots and virtual assistants will diversify their speech and understand all the nuances in our language. Also, self-supervision technology eliminates the need for large volumes of data, which makes it possible to quickly but accurately develop solutions for new languages and domains.
Use Cases:
HuBERT can be used for more profound speech understanding, which can potentially improve the existing applications that work with audio and simplify the development of new ones. Furthermore, it can be a preprocessing tool for further machine learning models, especially in natural language processing tasks. With all the latest insights provided by HuBERT representations, the work of many NLP models can be significantly improved. Learn more in nlp services.
Apart from that, speech representations from HuBERT can be utilized for synthesizing speech. HuBERT generated samples can compete in quality with all the previous supervised language models. You can even listen to some of the examples here.
 HuBERT’s performance for speech generation (source)
HuBERT’s performance for speech generation (source)
Finally, HuBERT is great at audio compressing. Listen to samples of compressed audio here.
Final Words:
Just like babies learn through listening and interacting with others, the models can learn from audio. It includes many aspects of a human language other than word spellings and syntax: intonation, emotions, interruptions, etc. And HuBERT is developed precisely for that. The ability to distinguish between different sounds and noises and correctly interpret all the parts of speech would make artificial intelligence truly intelligent. Chappie is not science fiction anymore, but the looming future (without the unnecessary violence, of course).
Honorable Mentions
The three innovations described above are not the only ones. Many other exciting things have been developed, and here are some of them:
RMA (Rapid Motor Adaption)
RMA is an end-to-end system based on reinforcement learning. It is trained entirely in a simulation, and it enables legged robots to adapt to new and challenging terrain in a split of a second. With RMA, robots learn to adjust joint positions without any predefined patterns, making it possible to move in any environment considering multiple factors: from the amount of friction on a new surface to the weight of a backpack. RMA-integrated robots have shown incredible results, outperforming all previous models. They successfully walk across challenging environments, react to any changes, and do it extremely quickly.
 With RMA, a robot can adapt to any environment, even to a slippery oil-covered surface (source)
With RMA, a robot can adapt to any environment, even to a slippery oil-covered surface (source)
Wav2vec
Wav2vec is another speech recognition approach from Facebook AI. It allows building high-quality speech recognition models without any transcribed data at all. It is an incredible achievement since it provides a way to analyze data in any language, even if it does not have a written format. Wav2vec was tested on Swahili and Tatar languages (which are not particularly common) and has shown the ability to work with languages that do not have a large amount of labeled data. Compared to the previous state-of-the-art model, wav2vec has reduced the error rate by 57%.
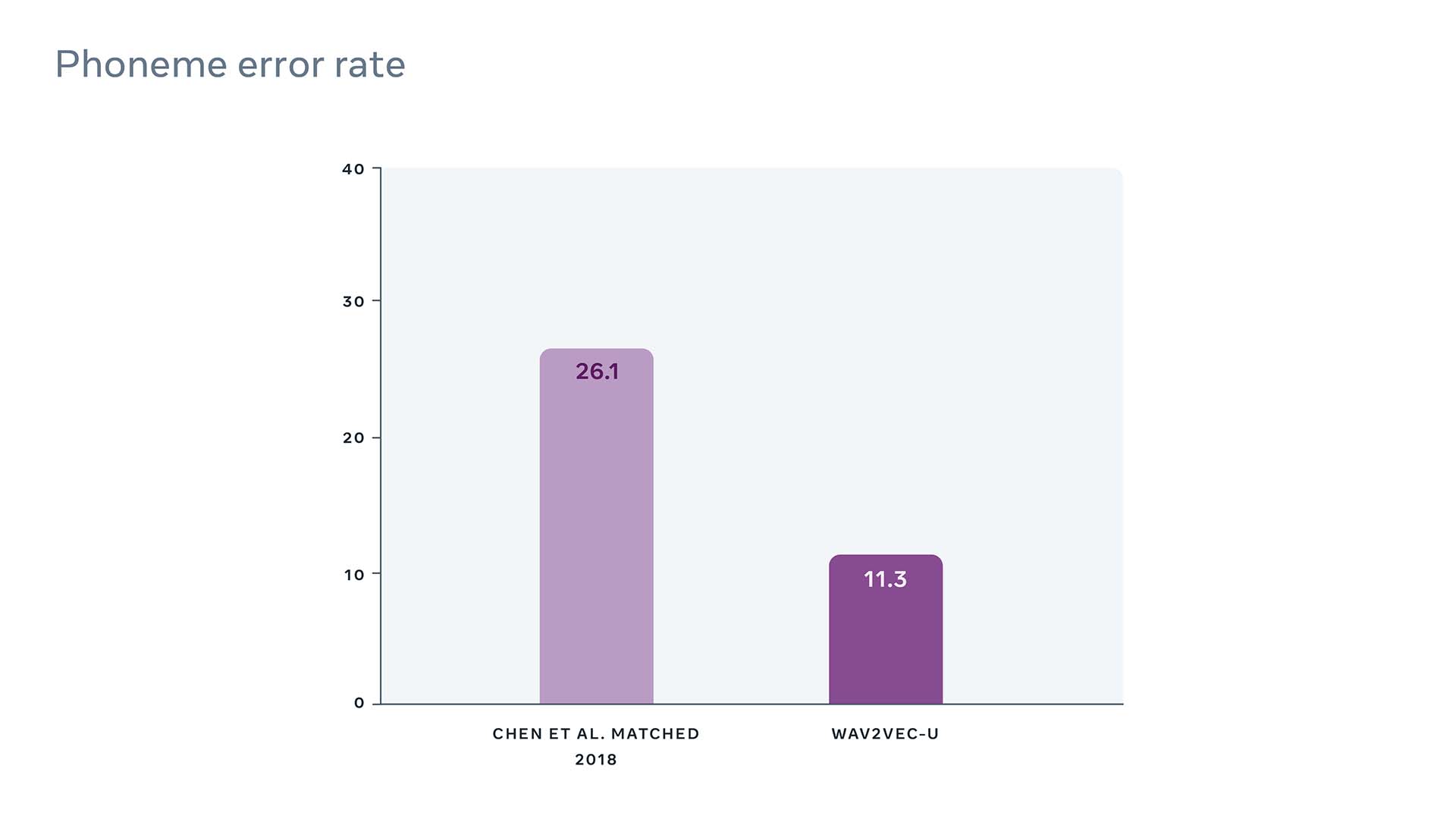 Wav2Vec compared with the previous best unsupervised method on the TIMIT benchmark (source)
Wav2Vec compared with the previous best unsupervised method on the TIMIT benchmark (source)
TextStyleBrush
TextStyleBrush is an AI project that can copy text style in a photo using just a single word. It is a new level of image editing and can potentially be used for future innovations like translating languages in augmented reality. This project is exciting because it is the first self-supervised model that replaces text in images of both handwriting and scenes using a single example word.
 Each image pair shows input source style on the left and output with new content on the right (source)
Each image pair shows input source style on the left and output with new content on the right (source)
GitHub Copilot
Copilot is an AI-based tool for programmers developed by Microsoft and OpenAI. It is an intelligent assistant that gives suggestions for whole lines or entire functions right in the editor. It is not a simple IDE-integrated autocomplete tool but an advanced pair programmer. Copilot was trained on billions of lines of public code available on GitHub. It supports all the most popular programming languages and frameworks and adapts individually to each developer.
Copilot is not yet a real programmer as it cannot write code by itself. However, it is an inspiring innovation that shows how powerful AI can be. It may grow into something huge in the future and even change the whole IT sphere.
Conclusions
The second quarter of this year has definitely been full of inventions. New models and approaches for different tasks were created, and with each of them, we are getting closer to the all-mighty artificial intelligence. Check out our optical character recognition services for more.
Facebook AI has stood out the most in this quarter, but the research is in full swing everywhere, so that we can expect many more breakthroughs in the near future.
Updated: 31.01.2023




