
What AI has achieved so far?
The 21st century is a very dynamic and continuously changing era. Technology is evolving at an enormous speed. Scientists are working harder than ever, and new cool things appear all the time. It’s almost the end of the year and there have already been many AI achievements. So, what has AI accomplished? This article will describe the most impressive latest AI achievements.
Without further ado, let’s see what has AI accomplished so far?
AI Explained: Definition and Core Mechanisms
AI is technology that allows machines to mimic human thinking. For example, recognize speech, analyze texts, find patterns in data, and even predict user behavior. This is not fantastic – these are practical tools that already today help businesses save time, reduce costs, and make accurate decisions.
In simple terms, AI works on the basis of algorithms that “learn” from data. The more high-quality information you provide to the system, the more accurate it becomes. For example, if you want to understand how a client behaves on your site, AI can analyze thousands of similar interactions and suggest what exactly to improve in marketing or the interface. For more info, refer to OCR scanning services.
There are several key components on which artificial intelligence is built:
Machine Learning is when algorithms are trained on examples. For example, they can “understand” which customers are more likely to buy a product and help you fine-tune your ads.
Natural Language Processing – helps systems understand texts like a person. This is important for chats, customer support and working with documents. If you want to know how exactly it can help, visit chatbot development services.
Computer Vision – allows AI to “see” and recognize objects in photos and videos. It is useful in production, safety, and medicine.
If you are CEO, CTO, or innovation management, the key issues that may concern you are:
How much does AI cost to implement?
Which business processes are most profitable to automate in the first place?
How quickly will I see the result?
How reliable are these technologies?
Who will help with development and maintenance?
The answer is simple: it all depends on the tasks, the amount of data and the level of readiness of your company for digital transformation. The good news is you don’t have to sort out the technical details. Our artificial intelligence development company with 9 years of experience will help you choose a solution for your specific business process and budget. The next step is to determine which processes in your company can be optimized now. AI is not about “expensive and difficult”. This is about “effective and profitable” if approached correctly.
DALL-E-3 and improved image generation
OpenAI’s most recent version of its groundbreaking text-to-image generating model, DALL-E 3, has immediately become one of the most notable AI accomplishments in computer vision. Computer vision developers use new capabilities like inpainting, which lets users change particular areas of an image by showing text modifications, have been added to DALL-E-3. This gives image production a new degree of control and accuracy. DALL-E-3’s legendary zero-shot capabilities, which enable it to produce incredibly imaginative and detailed images from even abstract or fantastical descriptions, remain present in the model.
How does it work? Building on the same framework as its predecessors, DALL-E-3 combines a large dataset of paired text and images with autoregressive transformers. Like natural language models, the model interprets input sequences as tokens, which it then uses to create or modify images. For instance, inpainting makes use of this tokenization to alter only specific areas of the image while maintaining the overall image’s coherence. DALL-E-3 can produce intricate and imaginative images from NLP services descriptions because it has been trained on billions of text-image pairs.
Why is it innovative? By improving image editing accuracy and expanding its capacity to manage intricate, sophisticated requests, DALL-E-3 expands on the innovation. It is perfect for real-world applications where customization is required because of the new inpainting functionality. Even in extremely strange situations, DALL-E-3 may produce visuals with unparalleled coherence, detail, and inventiveness because of transformer-based approaches, as opposed to GAN-based models. The model can produce entirely original visuals, which could help digital artists with problems like copyright infringement.

Use Cases: Because of its outstanding performance, DALL-E-3 has lots of use cases. Biggest AI achievements can be used in advertising, publishing, journalism, social media, etc., to create all types of illustrations: from mock-ups to complete designs. DALL-E might even solve the problem of copyrighting, as it can create unique images for any purpose, whether it is for a school project, a musical album cover, or an advertising campaign. Finally, this model can generate design ideas: there is no need to draw sketches anymore; you can simply write your thoughts as a text and choose the best option DALL-E -3 produces. For example, being a furniture designer, wouldn’t you find some of those armchairs in the shape of a Rubik’s cube awesome?
Companies that use it: DALL-E-3 is integrated into Microsoft’s new graphic design tool, Microsoft Designer, which allows users to generate high-quality social media posts, invitations, and other visual content. DALL-E is also used in Bing Image Creator to help users generate images when web results fall short.
CLIP
CLIP (Contrastive Language-Image Pre-training) is another neural network developed by OpenAI. It provides a powerful bridge between computer vision and natural language processing and opens many new opportunities. CLIP was designed to solve some of the main computer vision problems, including labor-intensive and costly labeling for datasets, low adaptability to new tasks, and poor real-world performance. Unlike traditional classification models, CLIP does not recognize the objects on an image but provides the most appropriate description. This approach gives more flexibility and robustness to non-standard datasets. CLIP outperformed the older ImageNet model on 20 out of 26 different datasets tested. Particularly interesting is its result on an adversarial dataset that is explicitly designed for confusing AI models. 77.1% accuracy is an incredible result which proves CLIP to be robust to previously unseen images, showcasing its advancement in machine learning classification algorithms.
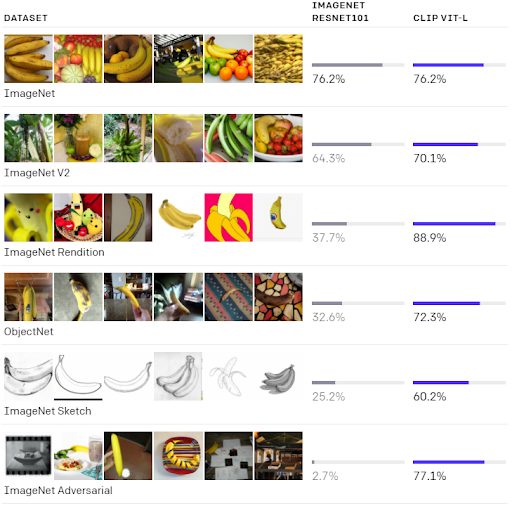
Comparison of ImageNet and CLIP performance across multiple datasets, highlighting differences in accuracy and generalization ability.
How does it work? CLIP was trained on 400 million image-text pairs. These are images found on the Internet and their captions. For example, a picture of a puppy sitting on the grass with the phrase “A photo of a puppy on the grass.” The model consists of two sub-models: a text encoder and an image encoder. Each of these converts texts or images into a mathematical space (vector representation). These vector representations allow us to compare how close the objects are. Ideally, the phrase “A photo of a puppy on the grass” must be as close to the picture of a puppy sitting on the grass as possible. This is precisely what happens during the training phase. The model tries to maximize the similarity between texts and their corresponding images. As a result, we receive a matrix with corresponding texts and pictures on the main diagonal (their similarity must be as high as possible) and unrelated texts and images elsewhere (their similarities must be as low as possible). Once the model is trained, we can get a text describing the image.
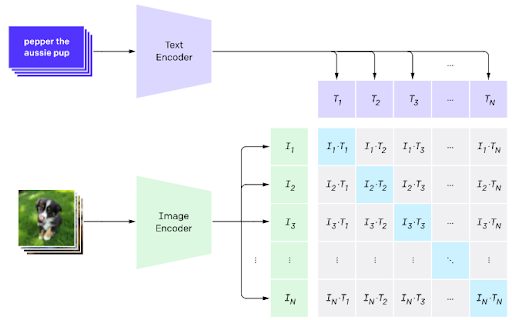
Why is it innovative? CLIP differs from other computer vision models in several ways. First of all, it does not need to construct a specific dataset, as it is already trained on a massive number of images taken from the Internet. As a result, no additional human effort is required. Secondly, CLIP has impressive zero-shot capabilities where a model can perform well on tasks it has never seen before. It utilizes semantics extracted from the text to add value to the images, making it possible to use CLIP for many different purposes without fine-tuning. It is different from the usual classification model that simply enumerates the classes and does not use the information provided by the text. Lastly, CLIP learns from unfiltered and noisy data, which adds to its flexibility and robustness and increases its accuracy on real-world data.
Use Cases: Even though it’s been only four months since the release of CLIP, there are several exciting applications already. This project uses CLIP to create a text-based interface for another model (StyleGAN), which, in turn, can generate and manipulate images. The result of its work can be a picture of a celebrity with another hairstyle. Also, this project can help you find a particular moment in a video by just entering its description and providing the video link. Another application would be a CLIP model in a Pictionary judge’s role, where it can decide how similar a picture is to the phrase. Finally, CLIP can be used as a discriminator for DALL-E (described above). Among many images generated by DALL-E, CLIP can choose the ones that correspond to the prompt the most, thus creating a robust image generation pipeline.

Companies that use it: Shutterstock uses CLIP to support the functionality of its AI-powered tools, particularly for generating and recognizing image content. CLIP helps Shutterstock’s users search for images by combining text and image inputs, improving the relevance of search results.
SEER
SEER (SElf-supERvised) is a self-supervised billion parameter computer vision model developed by Facebook AI. It can learn from any random set of images found on the Internet and does not need any preprocessing or labeling, which distinguishes it from all previous computer vision models. SEER was pre-trained on a billion random images publicly available on Instagram and reached an 84.2% accuracy on ImageNet, exceeding prior results. The model has also demonstrated state-of-the-art performance on various tasks, including object detection, segmentation, image classification, etc.
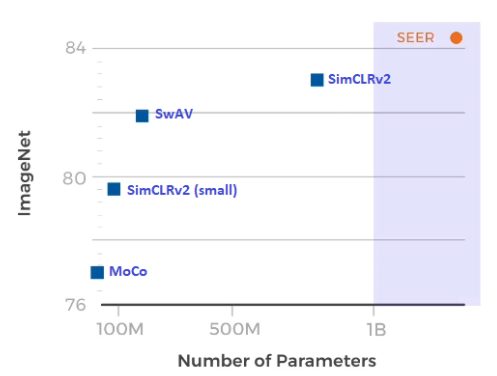
How does it work? Two major components are required to make SEER work efficiently with complex images. The first one is an algorithm that can work with a large number of pictures without labels. A new algorithm SwAV is used for this purpose. It can cluster related visual concepts quickly to make use of their similarities. The second component is a convolutional neural network that could effectively work with large and complex data without losing accuracy. RegNet models fit this need perfectly. They are capable of scaling to billions of parameters and show incredible accuracy. Lastly, Facebook AI also released an all-purpose library for self-supervised learning used for the development of SEER.
Why is it innovative? SEER has proved self-supervised learning to be a powerful instrument in AI’s development. It allows us to use the data that already exists in the world rather than specifically preparing it. This opens new possibilities for future AI research and allows for much more efficient real-world data usage. Training the models on real-life data increases its accuracy and ability to generalize, while simultaneously saving time and money that would otherwise be wasted on manual data preparation and labeling. Apart from that, self-supervised learning mitigates the biases that might arise during data annotation, problem definition in project becomes more flexible with self-supervised learning approaches.
Use Cases: SEER can be used for safety matters, such as identifying and removing hate or racist images rapidly. Aside from that, the model can potentially be used to automatically generate the description for images and better categorization of items sold. Finally, SEER’s efficiency and speed enable it to be used for medical purposes, including disease diagnosis. Learn more in data annotation services.
Companies that use it: Currently, SEER is primarily used by Meta for research purposes and to enhance its internal products, such as Instagram and Facebook, where it improves content moderation and personalized recommendations. Meta has also released the VISSL library, enabling other researchers and developers to apply SEER’s self-supervised learning techniques in various domains.
WaveNet
DeepMind created WaveNet, a deep generative model for producing unprocessed audio waveforms, particularly for speech and music. Instead of depending on conventional speech synthesis methods, it directly models sounds at the waveform level in an effort to create more realistic-sounding audio.
How does it work? WaveNet models the probability distribution of each individual audio sample using a convolutional neural network (CNN), which is conditioned on all prior samples. It creates a high-quality waveform by generating audio one sample at a time. It can mimic different speakers, accents, and even varied sound effects by learning from vast volumes of data.
Why is it innovative? WaveNet surpasses conventional techniques like parametric speech synthesis and concatenative synthesis, marking a substantial advancement in audio creation.
Use Cases: With its integration into services like Google Assistant and Google Translate, WaveNet has transformed text-to-speech (TTS) systems and produced voice output that sounds far more natural. Its capabilities also include creating music and sound effects for movies and video games, providing rich, high-fidelity audio that can be produced spontaneously without the need for pre-recorded content.
Companies that use it: Google uses WaveNet mostly in their Assistant and TTS products. Its technology has also helped platforms like YouTube improve the quality of their audio. Similar neural network models for voice synthesis have been incorporated into the products of other firms, such Voicery.
Honorable Mentions
Apart from DALL-E3, WaveNet, and SEER, there were other AI achievements in 2024-2025. Recent AI achievements might not be as significant as these AI accomplishments, but they are still shaping the future of AI, so it is important to know about them as well.
AlphaFold 3 from DeepMind
An updated version of the famous model is now able to predict not only the structure of proteins, but also their interaction with DNA, RNA and small molecules. This opens up completely new horizons in biotech and pharma – reducing the time and cost of drug development. For decision-makers, this means: R&D can be accelerated significantly, which means it can enter the market faster.
Sora by OpenAI
Text-video generator capable of creating full-fledged videos by text description. This is not just a marketing trick – Sora is already being tested to automatically generate commercials, train employees, and even simulate. This saves budgets and makes content easier to scale.
Mistral and Grok (from xAI)
These LLM models offer lighter and more open solutions than monolithic chats. They can be customized for specific business tasks, be it workflow, customer support or internal analytics. CTO and CDO are beginning to use them to optimize internal processes and reduce dependence on external platforms.
Gemini 1.5 from Google
This model is capable of “holding” up to 1 million tokens in context – and this is, in fact, a whole knowledge base or code base of the project. Now it is possible to build AI systems that not only respond to a request, but understand the history of the company, documentation and goals. This is especially true for companies with a large amount of internal data.
Autonomous Decision Functions in AI Agents
New versions of agent systems (for example, AutoGPT 2025 or Cognosys) have learned not only to perform tasks, but to plan steps themselves. It allows the business to automate not only the execution of tasks, but also the setting of goals. This is especially true for marketing, IT support and logistics. Our AI agent development company makes personalized solutions for your business. Check out for more!
AI Expands Into Creative Industries
AI has ceased to be a tool only for analytics – today it is actively involved in creative industries: cinema, music, design, advertising. And not as a “replacement for the artist”, but as an assistant who speeds up and reduces the cost of processes.
For example, designers use AI to generate concepts, covers, presentations. Marketers – to test dozens of banner and creative options that used to be made for weeks. Video production already uses generative models to create storyboards and even animations.
For decision-makers, this opens up opportunities: accelerate creative cycles, reduce content production costs, and test more ideas in a short time.
Artificial intelligence accomplishments are especially handy for digital agencies, e-commerce, media, educational projects, and startups that want to quickly scale visual or text content.
If earlier the work required a team of designers, copywriters, and producers, now AI takes on some of the tasks – and this is no longer a theory, but a practice, with an understandable effect on the budget.
Startups and Acquisitions Reshaping the AI Landscape
2024-2025 is the time of active transformation of the AI market. Large corporations buy promising startups to gain access to new technologies and teams.
Examples:
Microsoft is strengthening Copilot and Teams through niche developer purchases.
Amazon is investing in models optimized for voice assistants and advertising.
Salesforce acquires AI companies to customize CRM systems.
Nvidia builds an ecosystem around its GPUs through investments in startups that develop new types of models.
Key AI Trends
AI in healthcare
AI models have greatly increased their capacity to accurately identify conditions like cancer from MRIs, X-rays, and other scans. Better patient outcomes result from the earlier and more accurate diagnosis of illnesses made possible by these models. Physicians may now develop individualized treatment plans more quickly thanks to the broad use of AI in disciplines like pathology and radiology, which is accelerating diagnostic procedures. AI models assist radiologists in the detection of cancer by spotting early-stage cancers that would be hard to spot with the human eye. This enables earlier interventions and better results for patients. These achievements of AI are being used by companies such as GE Healthcare to improve medical imaging and diagnostics, increasing scan speed and accuracy. In order to help healthcare providers identify diseases in their early stages, when therapy is most successful, Google Health also employs artificial intelligence achievements to analyze medical scans. This is especially useful for early diagnosis of diseases like cancer.
AI-Driven Autonomous Vehicles
In AI achievements 2025, autonomous vehicles have made significant strides, particularly with companies like Waymo and Tesla deploying successful AI systems capable of handling more complex driving scenarios with fewer human interventions. Self-driving cars’ safety, navigation, and decision-making skills have improved because of the latest achievements of artificial intelligence to process real-time data from numerous sensors.
Deep learning, computer vision, and sensor fusion are all used in autonomous cars. The automobile can sense its environment, navigate highways, avoid obstructions, and obey traffic laws in real-time thanks to the AI algorithms that gather data from cameras, LIDAR, radar, and other sensors. The car’s comprehension of urban areas is improved by this sophisticated AI perception system. If you want to learn more about this, check out our image recognition software development services.
AI in Energy Optimization
The achievements of AI have made tremendous strides in energy management, especially in the areas of smart grid management, energy demand forecasting, and industrial energy usage optimization. In order to combat climate change, AI models are being utilized to improve energy systems’ efficiency and lower carbon emissions. To reduce waste, these models can optimize energy storage, integrate renewable energy sources, and modify power delivery. AI is also involved in smart grid management, guaranteeing effective energy flow according to current demands. While Tesla Energy employs the achievements of artificial intelligence to manage its energy storage systems, increasing grid stability and boosting overall energy management, Siemens uses AI to improve industrial energy use, guaranteeing more effective use of resources. How AI can help power & utilities? Learn more in our data analytics services.
Personalized Learning
AI is changing the way we learn. Algorithms analyze how a person learns material and adjust the pace, format, and content to suit it. It is especially useful for corporate training and online courses.
If you train employees or customers, OCR scanning service helps:
– Increase engagement, because everyone gets the right format
– Reduce training costs through automation
– Close knowledge gaps faster
Companies are already implementing such solutions within LMS, in training chatbots, and in AI simulators. It gives quick and measurable results, especially in sales, IT, customer support, and compliance areas.
Fraud Detection
AI is effective where you need to process large amounts of data and quickly identify anomalies – especially in the financial sector, e-commerce and insurance.
Algorithms can recognize suspicious transactions in real time, identify forgery attempts, and analyze user behavior and identify atypical actions.
Unlike classical rules and filters, AI is constantly learning, becoming more accurate, and reducing false positives. This reduces losses, speeds up checks and makes the client path more transparent.
Natural Language Processing
NLP is a technology that allows machines to “understand” text and speech. It already works in chatbots, recommendation systems, voice assistants, and feedback analysis tools.
In business, NLP solves the following problems: automatic processing of calls to support, analysis of customer sentiment by reviews and social networks, and search for insights in large volumes of texts (for example, legal documents)
With the help of natural language processing services, you can not only automate the routine, but understand customers more deeply and make decisions faster.
Personalized Treatment Options
Generative AI is ideal for developing tailored medicines. It can evaluate a person’s genetic information and assist in the development of pharmaceuticals that are tailored to their individual needs. This personalized strategy may result in improved health outcomes and fewer negative effects.
What’s Next for AI? A Glimpse into the Future
2026 will be the year when AI goes beyond individual tasks. We already see:
1.AI agents manage processes themselves – from marketing to logistics
2.Models are trained on their own actions, without manual adjustment
3.Companies move from pilots to full AI operations
The key trend is the integration of OCR scanning services (optical character recognition) into business as a system function, and not as “one of the projects”. It requires a strategic approach, a strong team, and a technological partner who understands not only algorithms, but also business tasks.
How do companies achieve the data-driven decision-making process?
At Data Science UA we assist companies in extracting real value from unstructured data sources
Final Thoughts
We have already witnessed several artificial intelligence achievements. DALL-E3 and CLIP are two revolutionary models that connect computer vision development services and solutions and natural language processing. At the same time, SEER has achieved state-of-the-art performance in computer vision and showed the power of self-supervised learning. Other related fields have had several AI accomplishments as well, and Data Science UA team would definitely love to implement them in our services. We can only guess what other amazing things await us in the future, and we can be confident that they will change the world.




