Overfitting and Underfitting
What are overfitting and underfitting?
Overfitting is a state of a machine learning model when it is overtrained. It happens when the model memorizes the data points and fits them too well. In this case, the accuracy on the train set is exceptionally high, while the accuracy on the test set is low. An overfitted model becomes useless when applied to new data. Overfitting usually happens when a too complicated algorithm is used for a simple pattern, or when the training continues too long, or when a dataset is simply too small.
On the other hand, underfitting is a state of the model when it is not trained enough. In this case, the model performs poorly on both the test and the train sets. Underfitting usually occurs when using an algorithm that is too simple and incapable of capturing the pattern in data.
In the figure below, three models are shown. The left one is too simple; it cannot be used to estimate the data points; thus, underfitting occurs. The middle model is the perfect one. It does not fit every single point, but it shows the pattern pretty well. The right model is an overfitted one. It has memorized all the data points and created an unbelievable pattern. Such a model will not be of much use for new data.
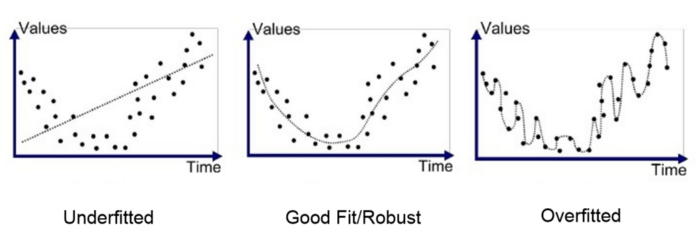 (source)
(source)
Why is it important?
Both under- and overfitting are indicators of a poorly trained model, and they need to be eliminated. Without the necessary attention, these concepts may make the model entirely useless.